State Threads is an application library which provides a foundation for writing fast and highly scalable Internet Applications on UNIX-like platforms. It combines the simplicity of the multithreaded programming paradigm, in which one thread supports each simultaneous connection, with the performance and scalability of an event-driven state machine architecture.
An Internet Application (IA) is either a server or client network application that accepts connections from clients and may or may not connect to servers. In an IA the arrival or departure of network data often controls processing (that is, IA is a data-driven application). For each connection, an IA does some finite amount of work involving data exchange with its peer, where its peer may be either a client or a server. The typical transaction steps of an IA are to accept a connection, read a request, do some finite and predictable amount of work to process the request, then write a response to the peer that sent the request. One example of an IA is a Web server; the most general example of an IA is a proxy server, because it both accepts connections from clients and connects to other servers.
We assume that the performance of an IA is constrained by available CPU cycles rather than network bandwidth or disk I/O (that is, CPU is a bottleneck resource).
1.2 Performance and Scalability
The performance of an IA is usually evaluated as its throughput measured in transactions per second or bytes per second (one can be converted to the other, given the average transaction size). There are several benchmarks that can be used to measure throughput of Web serving applications for specific workloads (such as SPECweb96, WebStone, WebBench). Although there is no common definition for scalability, in general it expresses the ability of an application to sustain its performance when some external condition changes. For IAs this external condition is either the number of clients (also known as "users," "simultaneous connections," or "load generators") or the underlying hardware system size (number of CPUs, memory size, and so on). Thus there are two types of scalability: load scalability and system scalability, respectively.
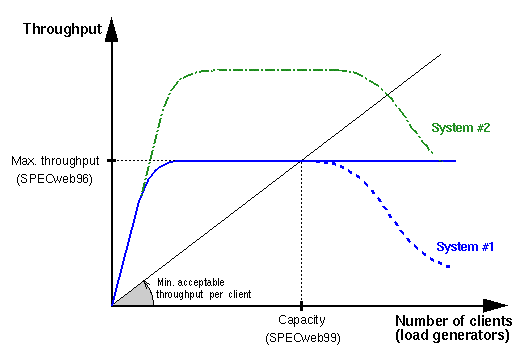
The figure below shows how the throughput of an idealized IA changes with the increasing number of clients (solid blue line). Initially the throughput grows linearly (the slope represents the maximal throughput that one client can provide). Within this initial range, the IA is underutilized and CPUs are partially idle. Further increase in the number of clients leads to a system saturation, and the throughput gradually stops growing as all CPUs become fully utilized. After that point, the throughput stays flat because there are no more CPU cycles available. In the real world, however, each simultaneous connection consumes some computational and memory resources, even when idle, and this overhead grows with the number of clients. Therefore, the throughput of the real world IA starts dropping after some point (dashed blue line in the figure below). The rate at which the throughput drops depends, among other things, on application design.
We say that an application has a good load scalability if it can sustain its throughput over a wide range of loads. Interestingly, the SPECweb99 benchmark somewhat reflects the Web server's load scalability because it measures the number of clients (load generators) given a mandatory minimal throughput per client (that is, it measures the server's capacity). This is unlike SPECweb96 and other benchmarks that use the throughput as their main metric (see the figure below).
System scalability is the ability of an application to sustain its performance per hardware unit (such as a CPU) with the increasing number of these units. In other words, good system scalability means that doubling the number of processors will roughly double the application's throughput (dashed green line). We assume here that the underlying operating system also scales well. Good system scalability allows you to initially run an application on the smallest system possible, while retaining the ability to move that application to a larger system if necessary, without excessive effort or expense. That is, an application need not be rewritten or even undergo a major porting effort when changing system size.
Although scalability and performance are more important in the case of server IAs, they should also be considered for some client applications (such as benchmark load generators).
Concurrency reflects the parallelism in a system. The two unrelated types are virtual concurrency and real concurrency.
An IA must provide virtual concurrency in order to serve many users simultaneously. To achieve maximum performance and scalability in doing so, the number of programming entities than an IA creates to be scheduled by the OS kernel should be kept close to (within an order of magnitude of) the real concurrency found on the system. These programming entities scheduled by the kernel are known as kernel execution vehicles. Examples of kernel execution vehicles include Solaris lightweight processes and IRIX kernel threads. In other words, the number of kernel execution vehicles should be dictated by the system size and not by the number of simultaneous connections.
There are a few different architectures that are commonly used by IAs. These include the Multi-Process, Multi-Threaded, and Event-Driven State Machine architectures.
2.1 Multi-Process Architecture
In the Multi-Process (MP) architecture, an individual process is dedicated to each simultaneous connection. A process performs all of a transaction's initialization steps and services a connection completely before moving on to service a new connection.
User sessions in IAs are relatively independent; therefore, no synchronization between processes handling different connections is necessary. Because each process has its own private address space, this architecture is very robust. If a process serving one of the connections crashes, the other sessions will not be affected. However, to serve many concurrent connections, an equal number of processes must be employed. Because processes are kernel entities (and are in fact the heaviest ones), the number of kernel entities will be at least as large as the number of concurrent sessions. On most systems, good performance will not be achieved when more than a few hundred processes are created because of the high context-switching overhead. In other words, MP applications have poor load scalability.
On the other hand, MP applications have very good system scalability, because no resources are shared among different processes and there is no synchronization overhead.
The Apache Web Server 1.x ([Reference 1]) uses the MP architecture on UNIX systems.
2.2 Multi-Threaded Architecture
In the Multi-Threaded (MT) architecture, multiple independent threads of control are employed within a single shared address space. Like a process in the MP architecture, each thread performs all of a transaction's initialization steps and services a connection completely before moving on to service a new connection.
Many modern UNIX operating systems implement a many-to-few model when mapping user-level threads to kernel entities. In this model, an arbitrarily large number of user-level threads is multiplexed onto a lesser number of kernel execution vehicles. Kernel execution vehicles are also known as virtual processors. Whenever a user-level thread makes a blocking system call, the kernel execution vehicle it is using will become blocked in the kernel. If there are no other non-blocked kernel execution vehicles and there are other runnable user-level threads, a new kernel execution vehicle will be created automatically. This prevents the application from blocking when it can continue to make useful forward progress.
Because IAs are by nature network I/O driven, all concurrent sessions block on network I/O at various points. As a result, the number of virtual processors created in the kernel grows close to the number of user-level threads (or simultaneous connections). When this occurs, the many-to-few model effectively degenerates to a one-to-one model. Again, like in the MP architecture, the number of kernel execution vehicles is dictated by the number of simultaneous connections rather than by number of CPUs. This reduces an application's load scalability. However, because kernel threads (lightweight processes) use fewer resources and are more light-weight than traditional UNIX processes, an MT application should scale better with load than an MP application.
Unexpectedly, the small number of virtual processors sharing the same address space in the MT architecture destroys an application's system scalability because of contention among the threads on various locks. Even if an application itself is carefully optimized to avoid lock contention around its own global data (a non-trivial task), there are still standard library functions and system calls that use common resources hidden from the application. For example, on many platforms thread safety of memory allocation routines (malloc(3), free(3), and so on) is achieved by using a single global lock. Another example is a per-process file descriptor table. This common resource table is shared by all kernel execution vehicles within the same process and must be protected when one modifies it via certain system calls (such as open(2), close(2), and so on). In addition to that, maintaining the caches coherent among CPUs on multiprocessor systems hurts performance when different threads running on different CPUs modify data items on the same cache line.
In order to improve load scalability, some applications employ a different type of MT architecture: they create one or more thread(s) per task rather than one thread per connection. For example, one small group of threads may be responsible for accepting client connections, another for request processing, and yet another for serving responses. The main advantage of this architecture is that it eliminates the tight coupling between the number of threads and number of simultaneous connections. However, in this architecture, different task-specific thread groups must share common work queues that must be protected by mutual exclusion locks (a typical producer-consumer problem). This adds synchronization overhead that causes an application to perform badly on multiprocessor systems. In other words, in this architecture, the application's system scalability is sacrificed for the sake of load scalability.
Of course, the usual nightmares of threaded programming, including data corruption, deadlocks, and race conditions, also make MT architecture (in any form) non-simplistic to use.
2.3 Event-Driven State Machine Architecture
In the Event-Driven State Machine (EDSM) architecture, a single process is employed to concurrently process multiple connections. The basics of this architecture are described in Comer and Stevens [Reference 2]. The EDSM architecture performs one basic data-driven step associated with a particular connection at a time, thus multiplexing many concurrent connections. The process operates as a state machine that receives an event and then reacts to it.
In the idle state the EDSM calls select(2) or poll(2) to wait for network I/O events. When a particular file descriptor is ready for I/O, the EDSM completes the corresponding basic step (usually by invoking a handler function) and starts the next one. This architecture uses non-blocking system calls to perform asynchronous network I/O operations. For more details on non-blocking I/O see Stevens [Reference 3].
To take advantage of hardware parallelism (real concurrency), multiple identical processes may be created. This is called Symmetric Multi-Process EDSM and is used, for example, in the Zeus Web Server ([Reference 4]). To more efficiently multiplex disk I/O, special "helper" processes may be created. This is called Asymmetric Multi-Process EDSM and was proposed for Web servers by Druschel and others [Reference 5].
EDSM is probably the most scalable architecture for IAs. Because the number of simultaneous connections (virtual concurrency) is completely decoupled from the number of kernel execution vehicles (processes), this architecture has very good load scalability. It requires only minimal user-level resources to create and maintain additional connection.
Like MP applications, Multi-Process EDSM has very good system scalability because no resources are shared among different processes and there is no synchronization overhead.
Unfortunately, the EDSM architecture is monolithic rather than based on the concept of threads, so new applications generally need to be implemented from the ground up. In effect, the EDSM architecture simulates threads and their stacks the hard way.
The State Threads library combines the advantages of all of the above architectures. The interface preserves the programming simplicity of thread abstraction, allowing each simultaneous connection to be treated as a separate thread of execution within a single process. The underlying implementation is close to the EDSM architecture as the state of each particular concurrent session is saved in a separate memory segment.
The state of each concurrent session includes its stack environment (stack pointer, program counter, CPU registers) and its stack. Conceptually, a thread context switch can be viewed as a process changing its state. There are no kernel entities involved other than processes. Unlike other general-purpose threading libraries, the State Threads library is fully deterministic. The thread context switch (process state change) can only happen in a well-known set of functions (at I/O points or at explicit synchronization points). As a result, process-specific global data does not have to be protected by mutual exclusion locks in most cases. The entire application is free to use all the static variables and non-reentrant library functions it wants, greatly simplifying programming and debugging while increasing performance. This is somewhat similar to a co-routine model (co-operatively multitasked threads), except that no explicit yield is needed -- sooner or later, a thread performs a blocking I/O operation and thus surrenders control. All threads of execution (simultaneous connections) have the same priority, so scheduling is non-preemptive, like in the EDSM architecture. Because IAs are data-driven (processing is limited by the size of network buffers and data arrival rates), scheduling is non-time-slicing.
Only two types of external events are handled by the library's scheduler, because only these events can be detected by select(2) or poll(2): I/O events (a file descriptor is ready for I/O) and time events (some timeout has expired). However, other types of events (such as a signal sent to a process) can also be handled by converting them to I/O events. For example, a signal handling function can perform a write to a pipe (write(2) is reentrant/asynchronous-safe), thus converting a signal event to an I/O event.
To take advantage of hardware parallelism, as in the EDSM architecture, multiple processes can be created in either a symmetric or asymmetric manner. Process management is not in the library's scope but instead is left up to the application.
There are several general-purpose threading libraries that implement a many-to-one model (many user-level threads to one kernel execution vehicle), using the same basic techniques as the State Threads library (non-blocking I/O, event-driven scheduler, and so on). For an example, see GNU Portable Threads ([Reference 6]). Because they are general-purpose, these libraries have different objectives than the State Threads library. The State Threads library is not a general-purpose threading library, but rather an application library that targets only certain types of applications (IAs) in order to achieve the highest possible performance and scalability for those applications.
State threads are very lightweight user-level entities, and therefore creating and maintaining user connections requires minimal resources. An application using the State Threads library scales very well with the increasing number of connections.
On multiprocessor systems an application should create multiple processes to take advantage of hardware parallelism. Using multiple separate processes is the only way to achieve the highest possible system scalability. This is because duplicating per-process resources is the only way to avoid significant synchronization overhead on multiprocessor systems. Creating separate UNIX processes naturally offers resource duplication. Again, as in the EDSM architecture, there is no connection between the number of simultaneous connections (which may be very large and changes within a wide range) and the number of kernel entities (which is usually small and constant). In other words, the State Threads library makes it possible to multiplex a large number of simultaneous connections onto a much smaller number of separate processes, thus allowing an application to scale well with both the load and system size.
Performance is one of the library's main objectives. The State Threads library is implemented to minimize the number of system calls and to make thread creation and context switching as fast as possible. For example, per-thread signal mask does not exist (unlike POSIX threads), so there is no need to save and restore a process's signal mask on every thread context switch. This eliminates two system calls per context switch. Signal events can be handled much more efficiently by converting them to I/O events (see above).
The library uses the same general, underlying concepts as the EDSM architecture, including non-blocking I/O, file descriptors, and I/O multiplexing. These concepts are available in some form on most UNIX platforms, making the library very portable across many flavors of UNIX. There are only a few platform-dependent sections in the source.
The State Threads library is a derivative of the Netscape Portable Runtime library (NSPR) [Reference 7]. The primary goal of NSPR is to provide a platform-independent layer for system facilities, where system facilities include threads, thread synchronization, and I/O. Performance and scalability are not the main concern of NSPR. The State Threads library addresses performance and scalability while remaining much smaller than NSPR. It is contained in 8 source files as opposed to more than 400, but provides all the functionality that is needed to write efficient IAs on UNIX-like platforms.
| NSPR | State Threads | |
|---|---|---|
| Lines of code | ~150,000 | ~3000 |
| Dynamic library size (debug version) |
||
| IRIX | ~700 KB | ~60 KB |
| Linux | ~900 KB | ~70 KB |
State Threads is an application library which provides a foundation for writing Internet Applications. To summarize, it has the following advantages:
The library's main limitation: